Kaggle Challenges
collection of Kaggle challenges I have participated in
Cover Image by Preethi Viswanathan on Unsplash
I have participated in four Kaggle challenges so far. My participation in the challenge Predict Future Sales was part of the Data Mining course and is described in the Data Mining project. The challenge G2Net-Hackathon is described in the Gravitational Wave Hackathon project. The other two challenges are described below.
Titanic - Machine Learning from Disaster
The Titanic challenge is a classic challenge for introducing beginners to the Kaggle platform. The challenge is to predict which passengers survived the Titanic shipwreck. The dataset contains the following information for each passenger:
- PassengerId: a unique identifier for each passenger
- Pclass: the class of the ticket (1st, 2nd, or 3rd)
- Name: the name of the passenger
- Sex: the sex of the passenger
- Age: the age of the passenger
- SibSp: the number of siblings/spouses aboard
- Parch: the number of parents/children aboard
- Ticket: the ticket number
- Fare: the ticket fare
- Cabin: the cabin number
- Embarked: the port of embarkation (C = Cherbourg, Q = Queenstown, S = Southampton)
The training dataset contains the information for 891 passengers, and the test dataset contains the information for 418 passengers. The test dataset does not contain the information about the survival of the passengers. The goal is to predict the survival of the passengers in the test dataset (0 = not survived, 1 = survived).
My goal for this challenge was to get familiar with the Kaggle platform and to practice on some decision tree algorithms. I used the following algorithms:
- Logistic Regression (LogReg)
- Light Gradient Boosting Machine (LightGBM)
- eXtreme Gradient Boosting (XGBoost)
For the data preprocessing, I dropped the columns for the passenger ID, name, ticket, and cabin. I mapped the sex and embarked columns to numerical values and filled the missing values in the age and fare columns with the mean values. For the samples that still had missing values, I dropped them from the training and test datasets. These decisions were made based on the exploratory data analysis I performed on the dataset, as well as practical considerations, since my goal for this challenge was to practice on some decision tree algorithms and get familiar with the Kaggle platform, rather than to achieve the best possible prediction.
I trained the algorithms on the training dataset and created a submission file for the test dataset. The submission file contained the passenger ID and the predicted survival. I made several submissions to the Kaggle platform for the different algorithms I used (for some of them I submitted multiple times). The scores I achieved are shown in the table below:
| Algorithm | Score |
|---|---|
| LogReg | 0.76794 |
| LightGBM | 0.77511 |
| XGBoost | 0.77751 |
The scores are based on the accuracy of the predictions. The best score I achieved was 0.77751 with the XGBoost algorithm. This score is on the top 30% of the leaderboard, which is not bad for the simple approach I used. The code for this challenge, with instructions on how to run it,can be found in the Titanic repository.
Spaceship Titanic
The Spaceship Titanic challenge is a fictional challenge that takes place in the year 2912. The challenge is to predict which passengers were transported by a spacetime anomaly using records recovered from the spaceship’s damaged computer system. The dataset contains the following information for each passenger:
- PassengerId: a unique identifier for each passenger
- HomePlanet: the home planet of the passenger
- CryoSleep: the passenger was in cryosleep (yes or no)
- Cabin: the cabin number
- Destination: the destination of the passenger
- Age: the age of the passenger
- VIP: the passenger was a VIP (yes or no)
- RoomService: the passenger used the room service
- FoodCourt: the passenger used the food court
- ShoppingMall: the passenger used the shopping mall
- Spa: the passenger used the spa
- VRDeck: the passenger used the VR deck
- Name: the name of the passenger
The training dataset contains the information for 8693 passengers, and the test dataset contains the information for 4277 passengers. The target variable is the Transported column, which indicates whether the passenger was transported by the spacetime anomaly (True or False).
For this challenge, I wanted to test many different models from the scikit-learn library and compare their performance. I also created a visualization notebook to get some useful insights from the data.
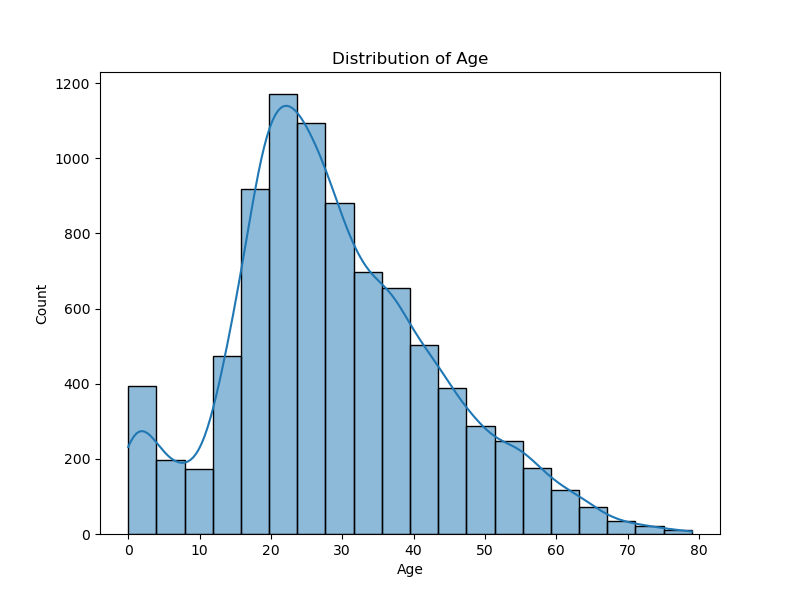
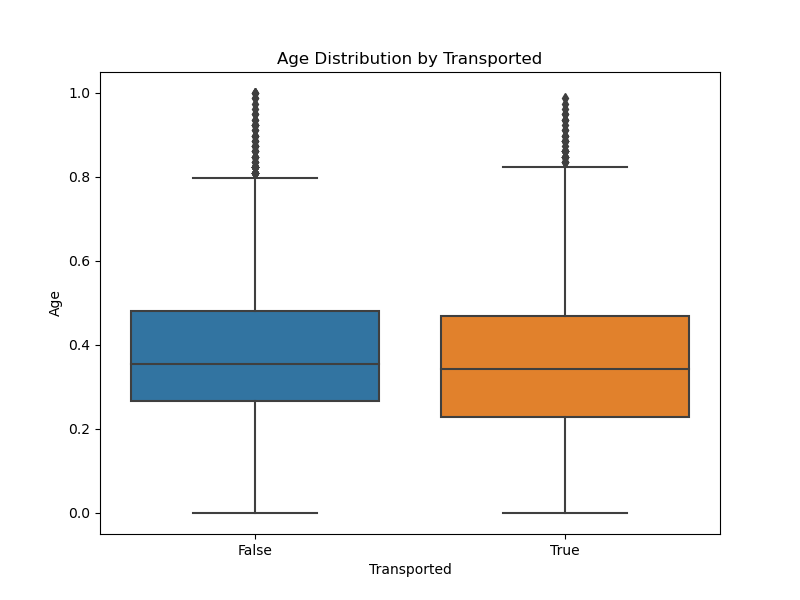
The full list of models I tested is as follows:
- AdaBoost
- Bagging
- ExtraTrees
- Gradient Boosting Machine (GBM)
- K-Nearest Neighbors (KNN)
- Logistic Regression
- Naive Bayes
- Neural Network
- Random Forest
- Support Vector Machine (SVM)
- Stacking (GBM and Random Forest)
- Decision Tree
- Voting (Majority Voting)
For some of the models, I also played with the hyperparameters to see if I could improve the performance. The voting model was created by combining the predictions of the Random Forest, GBM, AdaBoost, Bagging, Stacking, Neural Network, and SVM models. The majority voting was used to predict the final outcome.
In order to compare the performance of the models, I used the same preprocessing steps for all of them. I filled the missing values in the Age column with the median age, dropped the missing values, encoded the categorical variables, and scaled the numerical features. I also split the data into a training and a validation set (75% training, 25% validation).
The performance of the models was evaluated based on the accuracy of the predictions, as given by the Kaggle platform. The 5 models with the best performance are shown in the table below:
| Model | Accuracy |
|---|---|
| AdaBoost | 0.79541 |
| Gradient Boosting | 0.79237 |
| Bagging | 0.79191 |
| SVM | 0.79074 |
| Voting | 0.79074 |
The best score I achieved was 0.79541 with the AdaBoost model. This score is on the top 40% of the leaderboard, which is not a great result, but it was a good exercise to test many different models from a single library and compare their performance. Also the data preprocessing was not very complex, so I could focus more on the models themselves. The code for this challenge, with instructions on how to run it, can be found in the Spaceship Titanic repository.